





Define data flows, plugins, and logic using config files. Build with any editor or AI agent — your workflow, your rules.

Powered by open-source frameworks like Telegraf and the Python-like Starlark language. No steep learning curves.

The platform handles robustness, security, and integrations — so you don’t have to.
We enable organizations to deploy and maintain applications directly on IP (network) cameras—without extra hardware or cloud dependencies. Our services power both dev teams and enterprise IT with scalable deployment, monitoring, and lifecycle management.
Edge applications bundle all the code, configuration, and resources needed to extend your camera’s capabilities into a simple-to-install package. With an easy to use interface, your existing system integrator can easily install and configure the applications on the cameras you already have.
You used to be limited to the off-the-shelf applications, but now you can build or order custom applications designed specifically for you!

ACAP (Axis Camera Application Platform) is a robust, secure plugin platform for applications that run directly on Axis IP (network) cameras as background services. In other words: you can run analytics and integrations on the IP camera itself. It's an open platform that has been trusted for over 15 years in critical environments.

Axis IP devices are available in hundreds of models and with distributors and system integrators worldwide, making it easy to adapt to diverse environments. Applications can be installed by any system integrator or IT admin, with no need for external hardware or cloud.
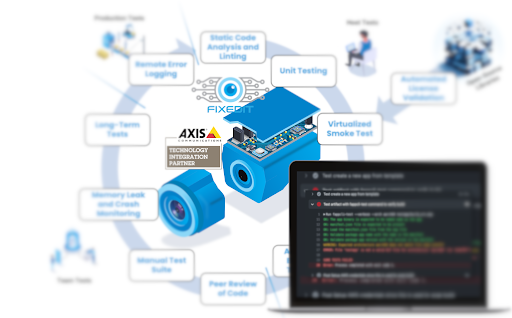
We specialize in scalable, production-grade edge applications for Axis cameras. Designed for long-term reliability, minimal overhead, and global deployment. As an official Technology Integration Partner, we deliver robust applications, signed by Axis and with full lifecycle support.

Beyond creating custom ACAP applications for you, we also offer the FixedIT Data Agent Platform — a powerful and much simpler way to develop, integrate, and scale your own edge solutions. Whether you’re a small team or a global enterprise, it gives you full control over your camera data, workflows, and automation.
The platform dramatically reduces the complexity of ACAP development. Your developers can build powerful on-camera applications without deep SDK or C/C++ knowledge, achieving high compatibility across models, easier maintenance, and fewer bugs. With configuration-based design and lightweight scripting, the Data Agent Platform brings enterprise reliability and developer simplicity together — making professional-grade edge apps faster to build and easier to scale.



"FixedIT's expertise was really helpful during development, as we could quickly get help from them in building our initial ACAP, saving us ton of time."
— Amruth Bhat, Lead Software Engineer at Voxela.ai
"The critical success factor was that FixedIT's services were geared towards empowering our internal team rather than delivering a pre-packaged solution."
— Jaime Santos, CEO AiTecServ
"The precompiled libraries save us time by eliminating the need for cross-compiling, and they are maintained, tested for compatibility by FixedIT and just work."
— Jana Schäfer, ACAP developer at AiTecServ
"The FixedIT CLI tool simplifies package development by automating common tasks and managing dependencies, making the process more efficient."
— Nithin Kalla, Developer at Voxela.ai
Enhance the skills of your ACAP developers, keep up to date with the new AXIS ACAP features and make onboarding of new employees to a breeze!
Our ACAP developer e-learning platform gives you easy access to our learning material. We have free content as well as premium deep dives. The material is available as video courses, text-based courses, follow-along exercises and interactive quizzes to test your knowledge.

Our clients are using our ACAP applications for everything ranging from simple rule based event filtering to advanced video analytics on the device. Our core focus is Machine Learning (ML), Deep Learning (DL) and Computer Vision (CV) for the Axis network cameras using the modern tool stack for Machine Learning Operations (MLOps) and Amazon Web Service (AWS) together with the Axis Camera Application Platform (ACAP).

Rule-Based Triggering &
Health Monitoring
Simple applications on your camera that monitors its status or reads its event streams. The applications are preconfigured to detect specific conditions such as combinations or sequences of events. When a condition is met the application produces a notification as a new event, HTTP push message or any other means of communication that can be received by a VMS or server.

Applications installed on the camera that can upload image or video data to a cloud provider, where video analytics are performed. These applications can also fetch configuration data from the cloud to customize the camera's and the application's behavior. The edge application can host a web-based user interface that allows any operator to configure or troubleshoot the application.

Edge ML applications use deep learning models or machine learning algorithms directly on the camera without requiring any additional hardware at the site. This can be achieved by using pre-trained models from a model zoo or by training custom models using TensorFlow. Some of the cameras has special hardware for ML (DLPU), while the other cameras can use CPU-based models. Edge ML can generate aggregated statistics or real-time event triggers based on the model output.
Our newsletter is a great way to stay informed about the latest innovations in video analytics and machine learning. We are always closely following developments in the Axis ACAP field, and we share our insights and opinions in our newsletter.
By signing up for our newsletter, you will be the first to know about the latest trends and innovations in video analytics and machine learning applied to surveillance cameras. You will also get exclusive access to our tips and tricks for developing machine learning applications on the edge with the ACAP SDK from Axis.
© 2021-2025 FixedIT Consulting AB
VAT: SE559296849801
Org. Number: 559296-8498
Phone: +46 76 80 156 12
Email: Daniel.Falk.1@FixedIT.ai
